서울시 범죄 현황
서울시는 25개의 자치구로 구성되어 있다. 서울시 5대 주요 범죄 발생 및 검거 데이터를 이용하여 각 자치구의 범죄현황에 대해 탐색하고자 한다.
분석에 사용한 데이터는 다음과 같다.
- 서울시 관서별 5대 범죄 발생 검거 현황 데이터(2017년 기준)
- 출처 : 공공데이터포털의 서울특별시 관서별 5대범죄 발생 검거현황(2000~2017)
- 정리된 데이터 다운로드 : seoul_crime_2000_2017.csv
- 경찰관서 주소 데이터
- 출처 : 경찰청의 전국경찰관서안내
- 정리된 데이터 다운로드 : police_address.csv
- 서울시 CCTV 현황 데이터(2017년 기준)
- CCTV 데이터 출처 : 서울열린데이터광장의 서울시 자치구 년도별 CCTV 설치 현황 - 2019.06.26 데이터 참조
- 정리된 데이터 다운로드 : seoul_cctv_b2011_2018.csv
- CCTV 데이터 출처 : 서울열린데이터광장의 서울시 자치구 년도별 CCTV 설치 현황 - 2019.06.26 데이터 참조
- 서울시 인구 데이터(2017년 기준)
- 인구 데이터 출처 : 서울열린데이터광장의 서울시 주민등록인구 (구별) 통계
- 정리된 데이터 다운로드 : seoul_pop_1992_2018.csv
패키지 준비
library(tidyverse)## Warning: 패키지 'readr'는 R 버전 4.1.1에서 작성되었습니다library(stringr)
library(gridExtra)
library(RColorBrewer)
library(GGally)데이터 불러오기 및 정리 (Import & Tidy)
서울시 관서별 5대 주요 범죄 데이터(2000년 ~ 2017년) 불러오기
scrime <- read.csv("data/seoul_crime_2000_2017.csv",
stringsAsFactors = FALSE, encoding = "euc-kr")
str(scrime)## 'data.frame': 5580 obs. of 5 variables:
## $ 구분 : chr "중부" "중부" "중부" "중부" ...
## $ 죄종 : chr "살인" "살인" "강도" "강도" ...
## $ 발생검거: chr "발생" "검거" "발생" "검거" ...
## $ 건수 : int 1 1 17 15 14 14 601 569 1783 1762 ...
## $ year : int 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...서울시 범죄 데이터 정리하기
# 2017년 기준으로 분석할 것이기 때문에 2017년 데이터만 추출
scrime <- scrime %>%
filter(year == 2017)# 분석의 편의를 위해 '발생검거'열을 2개의 열(발생, 검거) 로 나누고자 함
scrime <- scrime %>%
spread(key = "발생검거", value = "건수")
str(scrime)## 'data.frame': 155 obs. of 5 variables:
## $ 구분: chr "강남" "강남" "강남" "강남" ...
## $ 죄종: chr "강간" "강도" "살인" "절도" ...
## $ year: int 2017 2017 2017 2017 2017 2017 2017 2017 2017 2017 ...
## $ 검거: int 366 16 6 787 1942 169 12 6 949 2109 ...
## $ 발생: int 456 13 6 2069 2229 172 10 5 1645 2429 ...# 죄종을 5개의 열로 나누고 각 열별로 검거와 발생을 연결하여 정리하기
scrime <- scrime %>%
nest(검거, 발생, .key = "value_col") %>%
spread(key = "죄종", value = value_col) %>%
unnest(강간, 강도, 살인, 절도, 폭력, .sep = '')## Warning: All elements of `...` must be named.
## Did you want `value_col = c(검거, 발생)`?## Warning: unnest() has a new interface. See ?unnest for details.
## Try `df %>% unnest(c(강간, 강도, 살인, 절도, 폭력))`, with `mutate()` if needed## Warning: The `.sep` argument of `unnest()` is deprecated as of tidyr 1.0.0.
## Use `names_sep = ''` instead.str(scrime)## tibble [31 x 12] (S3: tbl_df/tbl/data.frame)
## $ 구분 : chr [1:31] "강남" "강동" "강북" "강서" ...
## $ year : int [1:31] 2017 2017 2017 2017 2017 2017 2017 2017 2017 2017 ...
## $ 강간검거: int [1:31] 366 169 153 253 323 208 181 212 62 155 ...
## $ 강간발생: int [1:31] 456 172 208 316 379 261 328 240 94 180 ...
## $ 강도검거: int [1:31] 16 12 5 6 6 8 6 5 3 7 ...
## $ 강도발생: int [1:31] 13 10 7 4 7 13 8 5 3 9 ...
## $ 살인검거: int [1:31] 6 6 8 11 7 5 8 5 0 4 ...
## $ 살인발생: int [1:31] 6 5 8 11 8 6 7 5 1 4 ...
## $ 절도검거: int [1:31] 787 949 635 1113 1152 1168 869 674 400 757 ...
## $ 절도발생: int [1:31] 2069 1645 1014 1888 1979 2220 1725 1141 785 1538 ...
## $ 폭력검거: int [1:31] 1942 2109 2023 2544 2666 1900 2344 1676 780 2124 ...
## $ 폭력발생: int [1:31] 2229 2429 2156 2916 3152 2146 2827 1874 863 2478 ...# 구분(경찰서명)의 앞과 뒤에 "서울"과 "경찰서" 붙이기(예, 중부 -> 서울중부경찰서)
scrime <- scrime %>%
mutate(구분 = paste0("서울", 구분, "경찰서"))
scrime %>% print(n = Inf)## # A tibble: 31 x 12
## 구분 year 강간검거 강간발생 강도검거 강도발생 살인검거 살인발생 절도검거
## <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 서울강남~ 2017 366 456 16 13 6 6 787
## 2 서울강동~ 2017 169 172 12 10 6 5 949
## 3 서울강북~ 2017 153 208 5 7 8 8 635
## 4 서울강서~ 2017 253 316 6 4 11 11 1113
## 5 서울관악~ 2017 323 379 6 7 7 8 1152
## 6 서울광진~ 2017 208 261 8 13 5 6 1168
## 7 서울구로~ 2017 181 328 6 8 8 7 869
## 8 서울금천~ 2017 212 240 5 5 5 5 674
## 9 서울남대~ 2017 62 94 3 3 0 1 400
## 10 서울노원~ 2017 155 180 7 9 4 4 757
## 11 서울도봉~ 2017 115 104 3 3 1 1 417
## 12 서울동대~ 2017 149 165 5 3 10 11 1017
## 13 서울동작~ 2017 173 396 9 7 1 1 593
## 14 서울마포~ 2017 429 500 8 8 3 3 837
## 15 서울방배~ 2017 60 65 5 4 2 1 176
## 16 서울서대~ 2017 181 202 2 1 4 4 719
## 17 서울서부~ 2017 79 93 2 2 3 3 375
## 18 서울서초~ 2017 223 405 2 9 8 8 659
## 19 서울성동~ 2017 106 132 3 3 1 1 543
## 20 서울성북~ 2017 72 107 5 5 5 5 332
## 21 서울송파~ 2017 242 288 3 1 6 6 1026
## 22 서울수서~ 2017 130 151 8 7 1 1 596
## 23 서울양천~ 2017 122 138 2 3 2 3 756
## 24 서울영등~ 2017 267 455 5 5 13 15 1108
## 25 서울용산~ 2017 289 327 4 5 1 1 626
## 26 서울은평~ 2017 134 137 2 2 3 3 559
## 27 서울종로~ 2017 103 131 4 5 3 5 360
## 28 서울종암~ 2017 62 66 3 3 2 2 371
## 29 서울중랑~ 2017 144 172 4 3 5 5 813
## 30 서울중부~ 2017 87 173 6 6 0 0 489
## 31 서울혜화~ 2017 70 122 4 5 2 2 298
## # ... with 3 more variables: 절도발생 <int>, 폭력검거 <int>, 폭력발생 <int>경찰서의 주소를 찾아 경찰서가 위치한 자치구 변수 추가
# 경찰서 주소가 들어있는 데이터 불러오기
police_addr <- read.csv("data/police_address.csv", stringsAsFactors = FALSE)
str(police_addr)## 'data.frame': 273 obs. of 4 variables:
## $ province: chr "서울" "서울" "서울" "서울" ...
## $ office : chr "서울지방경찰청" "서울강남경찰서" "서울강동경찰서" "서울강북경찰서" ...
## $ address : chr "서울시 종로구 사직로8길 31" "서울시 강남구 테헤란로 114길 11" "서울시 강동구 성내로 57" "서울시 강북구 오패산로 406" ...
## $ website : chr "http://www.smpa.go.kr/" "http://www.smpa.go.kr/gn/" "http://www.smpa.go.kr/gd/" "http://www.smpa.go.kr/gb/" ...# 엑셀 vlookup과 유사한 함수 (this=찾는값, df=데이터, key=찾는변수, value=얻는값 )
vlookup <- function(this, df, key, value) {
m <- match(this, df[[key]])
df[[value]][m]
}# 경찰서명에 맞는 주소를 찾아 새로운 변수에 입력하기
scrime <- scrime %>%
mutate(주소 = vlookup(구분, police_addr, "office", "address"))
scrime %>% select(구분, 주소) %>% print(n = Inf)## # A tibble: 31 x 2
## 구분 주소
## <chr> <chr>
## 1 서울강남경찰서 서울시 강남구 테헤란로 114길 11
## 2 서울강동경찰서 서울시 강동구 성내로 57
## 3 서울강북경찰서 서울시 강북구 오패산로 406
## 4 서울강서경찰서 서울시 양천구 화곡로 73
## 5 서울관악경찰서 서울시 관악구 관악로5길 33
## 6 서울광진경찰서 서울시 광진구 자양로 167
## 7 서울구로경찰서 서울시 구로구 가마산로 235
## 8 서울금천경찰서 서울시 금천구 시흥대로73길 50
## 9 서울남대문경찰서 서울시 중구 한강대로 410
## 10 서울노원경찰서 서울시 노원구 노원로 283
## 11 서울도봉경찰서 서울시 도봉구 노해로 403
## 12 서울동대문경찰서 서울시 동대문구 약령시로21길 29
## 13 서울동작경찰서 서울시 동작구 노량진로 148
## 14 서울마포경찰서 서울시 마포구 마포대로 183
## 15 서울방배경찰서 서울시 서초구 동작대로 204
## 16 서울서대문경찰서 서울 서대문구 통일로 113
## 17 서울서부경찰서 서울시 은평구 통일로 757
## 18 서울서초경찰서 서울시 서초구 반포대로 179
## 19 서울성동경찰서 서울시 성동구 왕십리광장로 9
## 20 서울성북경찰서 서울 성북구 보문로 170
## 21 서울송파경찰서 서울시 송파구 중대로 221
## 22 서울수서경찰서 서울시 강남구 개포로 617
## 23 서울양천경찰서 서울시 양천구 목동동로 99
## 24 서울영등포경찰서 서울시 영등포구 국회대로 608
## 25 서울용산경찰서 서울시 용산구 원효로89길 24
## 26 서울은평경찰서 서울시 은평구 연서로 365
## 27 서울종로경찰서 서울시 종로구 율곡로 46
## 28 서울종암경찰서 서울시 성북구 종암로 135
## 29 서울중랑경찰서 서울시 중랑구 신내역로3길 40-10
## 30 서울중부경찰서 서울시 중구 수표로 27
## 31 서울혜화경찰서 서울시 종로구 창경궁로 112-16# 주소에서 두번째에 있는 자치구 이름만 추출하여 새로운 변수(자치구)에 입력하기
scrime <- scrime %>%
separate(주소, c(NA, "자치구"), sep = " ", extra = "drop")# 자치구를 기준으로 정렬하여 경찰서와 자치구 출력
scrime %>% select(구분, 자치구) %>% arrange(자치구) %>% print(n = Inf)## # A tibble: 31 x 2
## 구분 자치구
## <chr> <chr>
## 1 서울강남경찰서 강남구
## 2 서울수서경찰서 강남구
## 3 서울강동경찰서 강동구
## 4 서울강북경찰서 강북구
## 5 서울관악경찰서 관악구
## 6 서울광진경찰서 광진구
## 7 서울구로경찰서 구로구
## 8 서울금천경찰서 금천구
## 9 서울노원경찰서 노원구
## 10 서울도봉경찰서 도봉구
## 11 서울동대문경찰서 동대문구
## 12 서울동작경찰서 동작구
## 13 서울마포경찰서 마포구
## 14 서울서대문경찰서 서대문구
## 15 서울방배경찰서 서초구
## 16 서울서초경찰서 서초구
## 17 서울성동경찰서 성동구
## 18 서울성북경찰서 성북구
## 19 서울종암경찰서 성북구
## 20 서울송파경찰서 송파구
## 21 서울강서경찰서 양천구
## 22 서울양천경찰서 양천구
## 23 서울영등포경찰서 영등포구
## 24 서울용산경찰서 용산구
## 25 서울서부경찰서 은평구
## 26 서울은평경찰서 은평구
## 27 서울종로경찰서 종로구
## 28 서울혜화경찰서 종로구
## 29 서울남대문경찰서 중구
## 30 서울중부경찰서 중구
## 31 서울중랑경찰서 중랑구구를 기준으로 정렬한 결과, 7개 구에 2개의 경찰서가 있는 것으로 나타남. 서울강서경찰서는 현재 양천구 임시청사에 있으나 관할구역은 강서구임.
# 서울강서경찰서의 자치구를 강서구로 수정함
scrime <- scrime %>%
mutate(자치구 = replace(자치구, which(구분 == "서울강서경찰서"), "강서구"))서울시 자치구의 수는 25개임. 강남과 수서는 강남구, 서초와 방배는 서초구, 성북과 종암은 성북구, 서부와 은평은 은평구, 종로와 혜화는 종로구, 중부와 남대문은 중구를 관할함.
# 자치구를 기준으로 변수들을 통합함(구분, year 변수는 삭제)
scrime <- scrime %>%
group_by(자치구) %>%
summarise(강간검거 = sum(강간검거),
강간발생 = sum(강간발생),
강도검거 = sum(강도검거),
강도발생 = sum(강도발생),
살인검거 = sum(살인검거),
살인발생 = sum(살인발생),
절도검거 = sum(절도검거),
절도발생 = sum(절도발생),
폭력검거 = sum(폭력검거),
폭력발생 = sum(폭력발생))이상으로 2017년 기준 서울시 자치구별 5대 범죄의 발생과 검거 건수를 정리함
# 서울시 범죄 데이터 정리 결과 보기
scrime %>% print(n = Inf, width = Inf)## # A tibble: 25 x 11
## 자치구 강간검거 강간발생 강도검거 강도발생 살인검거 살인발생 절도검거
## <chr> <int> <int> <int> <int> <int> <int> <int>
## 1 강남구 496 607 24 20 7 7 1383
## 2 강동구 169 172 12 10 6 5 949
## 3 강북구 153 208 5 7 8 8 635
## 4 강서구 253 316 6 4 11 11 1113
## 5 관악구 323 379 6 7 7 8 1152
## 6 광진구 208 261 8 13 5 6 1168
## 7 구로구 181 328 6 8 8 7 869
## 8 금천구 212 240 5 5 5 5 674
## 9 노원구 155 180 7 9 4 4 757
## 10 도봉구 115 104 3 3 1 1 417
## 11 동대문구 149 165 5 3 10 11 1017
## 12 동작구 173 396 9 7 1 1 593
## 13 마포구 429 500 8 8 3 3 837
## 14 서대문구 181 202 2 1 4 4 719
## 15 서초구 283 470 7 13 10 9 835
## 16 성동구 106 132 3 3 1 1 543
## 17 성북구 134 173 8 8 7 7 703
## 18 송파구 242 288 3 1 6 6 1026
## 19 양천구 122 138 2 3 2 3 756
## 20 영등포구 267 455 5 5 13 15 1108
## 21 용산구 289 327 4 5 1 1 626
## 22 은평구 213 230 4 4 6 6 934
## 23 종로구 173 253 8 10 5 7 658
## 24 중구 149 267 9 9 0 1 889
## 25 중랑구 144 172 4 3 5 5 813
## 절도발생 폭력검거 폭력발생
## <int> <int> <int>
## 1 3130 3411 3956
## 2 1645 2109 2429
## 3 1014 2023 2156
## 4 1888 2544 2916
## 5 1979 2666 3152
## 6 2220 1900 2146
## 7 1725 2344 2827
## 8 1141 1676 1874
## 9 1538 2124 2478
## 10 633 1116 1258
## 11 1547 2093 2249
## 12 1226 1466 1700
## 13 2094 2222 2673
## 14 1230 1393 1676
## 15 1812 2102 2404
## 16 1072 1378 1559
## 17 1344 1627 1902
## 18 2274 2593 3007
## 19 1590 1778 2148
## 20 2304 2619 3190
## 21 1346 2016 2381
## 22 1387 2050 2256
## 23 1644 1837 2143
## 24 1846 1804 2061
## 25 1533 2426 2858서울시 인구 데이터 불러오기
# 서울시 인구 데이터 불러오기
spop <- read.csv("data/seoul_pop_1992_2018.csv", stringsAsFactors = FALSE)
str(spop)## 'data.frame': 693 obs. of 16 variables:
## $ 연도 : int 1992 1992 1992 1992 1992 1992 1992 1992 1992 1992 ...
## $ 자치구 : chr "합계" "종로구" "중구" "용산구" ...
## $ 세대 : int 3383169 75752 59667 96832 244888 149094 136876 163995 229923 174005 ...
## $ 인구 : int 10969862 227988 176836 287124 780526 470594 458391 527296 766799 571833 ...
## $ 남자 : int 5519096 114648 89537 144600 397121 238385 230937 266530 385385 284049 ...
## $ 여자 : int 5450766 113340 87299 142524 383405 232209 227454 260766 381414 287784 ...
## $ 한국인 : int 10935230 226240 174605 280671 778385 469843 458109 525943 765975 571171 ...
## $ 한국인남자: int 5500001 113677 88268 140424 395977 237979 230799 265830 385011 283705 ...
## $ 한국인여자: int 5435229 112563 86337 140247 382408 231864 227310 260113 380964 287466 ...
## $ 외국인 : int 34632 1748 2231 6453 2141 751 282 1353 824 662 ...
## $ 외국인남자: int 19095 971 1269 4176 1144 406 138 700 374 344 ...
## $ 외국인여자: int 15537 777 962 2277 997 345 144 653 450 318 ...
## $ 인구밀도 : chr "18121" "9496" "17701" "13135" ...
## $ 면적 : chr "605.36" "24.01" "9.99" "21.86" ...
## $ 세대당인구: num 3.24 3.01 2.96 2.97 3.19 3.16 3.35 3.22 3.34 3.29 ...
## $ 고령자 : int 434348 12096 8857 13957 28493 19142 15849 23020 29689 24345 ...서울시 인구 데이터 정리하기
# 2017년도 자치구, 인구, 한국인, 외국인, 고령자, 인구밀도, 면적 데이터 추출
spop2017 <- spop %>%
filter(연도 == 2017) %>%
select(자치구, 인구, 한국인, 외국인, 고령자, 세대) 데이터의 첫번째 행에 있는 합계는 필요 없으로 삭제함
# 첫번째 행(합계) 삭제
spop2017 <- spop2017[-1,]
str(spop2017) ## 'data.frame': 25 obs. of 6 variables:
## $ 자치구: chr "종로구" "중구" "용산구" "성동구" ...
## $ 인구 : int 164257 134593 244444 312711 372298 366011 412780 455407 328002 346234 ...
## $ 한국인: int 154770 125709 229161 304808 357703 350647 408226 444055 324479 344166 ...
## $ 외국인: int 9487 8884 15283 7903 14595 15364 4554 11352 3523 2068 ...
## $ 고령자: int 26182 21384 36882 41273 43953 55718 59262 66251 56530 53488 ...
## $ 세대 : int 73594 60412 107666 132902 160798 159938 179132 187112 142533 137378 ...# 외국인비율과 고령자비율 변수 추가
spop2017 <- spop2017 %>%
mutate(외국인비율 = 외국인 / 인구 * 100,
고령자비율 = 고령자 / 인구 * 100)
head(spop2017)## 자치구 인구 한국인 외국인 고령자 세대 외국인비율 고령자비율
## 2 종로구 164257 154770 9487 26182 73594 5.775705 15.93966
## 3 중구 134593 125709 8884 21384 60412 6.600640 15.88790
## 4 용산구 244444 229161 15283 36882 107666 6.252148 15.08812
## 5 성동구 312711 304808 7903 41273 132902 2.527254 13.19845
## 6 광진구 372298 357703 14595 43953 160798 3.920247 11.80587
## 7 동대문구 366011 350647 15364 55718 159938 4.197688 15.22304서울시 CCTV 데이터 불러오기
# 서울시 CCTV 설치 현황(2011년이전 ~ 2018년) 데이터 불러오기
scctv <- read.csv("data/seoul_cctv_b2011_2018.csv", stringsAsFactors = FALSE)
str(scctv)## 'data.frame': 25 obs. of 10 variables:
## $ 기관명 : chr "강 남 구" "강 동 구" "강 북 구" "강 서 구" ...
## $ 소계 : int 5221 1879 1265 1617 3985 1581 3227 1634 1906 858 ...
## $ X2011년이전: int 1944 303 243 219 430 470 852 27 481 197 ...
## $ X2012년 : int 195 387 88 155 56 42 219 17 117 66 ...
## $ X2013년 : int 316 134 141 118 419 83 349 242 203 8 ...
## $ X2014년 : int 430 59 74 230 487 87 187 101 80 185 ...
## $ X2015년 : int 546 144 145 187 609 64 268 382 461 59 ...
## $ X2016년 : int 765 194 254 190 619 21 326 136 298 155 ...
## $ X2017년 : int 577 273 1 264 694 468 540 199 110 117 ...
## $ X2018년 : int 448 385 319 254 671 346 486 530 156 71 ...서울시 CCTV 데이터 정리하기
데이터는 각 년도별로 설치된 대수와 2018년까지의 소계를 보여주고 있다. 2017년까지 설치된 CCTV 누적대수는 소계에서 2018년 설치대수를 빼는 방식으로 계산하고자 한다.
# 2017년 기준 CCTV 설치누적대수 산출하기
scctv2017 <- scctv %>%
mutate(cctv2017 = 소계 - X2018년) %>%
select(기관명, cctv2017)
str(scctv2017)## 'data.frame': 25 obs. of 2 variables:
## $ 기관명 : chr "강 남 구" "강 동 구" "강 북 구" "강 서 구" ...
## $ cctv2017: int 4773 1494 946 1363 3314 1235 2741 1104 1750 787 ...# 기관명을 자치구로 변수명 변경
scctv2017 <- scctv2017 %>% rename(자치구 = 기관명)# 자치구 글자 사이에 공백이 있으므로 이를 제거
scctv2017$자치구 <- str_replace_all(scctv2017$자치구, " ", "")
head(scctv2017)## 자치구 cctv2017
## 1 강남구 4773
## 2 강동구 1494
## 3 강북구 946
## 4 강서구 1363
## 5 관악구 3314
## 6 광진구 1235자치구를 기준으로 범죄, 인구, CCTV 데이터 병합하기
# scrime, spop2017, scctv2017 병합
seoul_crime_pop_cctv <- list(scrime, spop2017, scctv2017) %>%
reduce(left_join, by = "자치구")
str(seoul_crime_pop_cctv)## tibble [25 x 19] (S3: tbl_df/tbl/data.frame)
## $ 자치구 : chr [1:25] "강남구" "강동구" "강북구" "강서구" ...
## $ 강간검거 : int [1:25] 496 169 153 253 323 208 181 212 155 115 ...
## $ 강간발생 : int [1:25] 607 172 208 316 379 261 328 240 180 104 ...
## $ 강도검거 : int [1:25] 24 12 5 6 6 8 6 5 7 3 ...
## $ 강도발생 : int [1:25] 20 10 7 4 7 13 8 5 9 3 ...
## $ 살인검거 : int [1:25] 7 6 8 11 7 5 8 5 4 1 ...
## $ 살인발생 : int [1:25] 7 5 8 11 8 6 7 5 4 1 ...
## $ 절도검거 : int [1:25] 1383 949 635 1113 1152 1168 869 674 757 417 ...
## $ 절도발생 : int [1:25] 3130 1645 1014 1888 1979 2220 1725 1141 1538 633 ...
## $ 폭력검거 : int [1:25] 3411 2109 2023 2544 2666 1900 2344 1676 2124 1116 ...
## $ 폭력발생 : int [1:25] 3956 2429 2156 2916 3152 2146 2827 1874 2478 1258 ...
## $ 인구 : int [1:25] 561052 440359 328002 608255 520929 372298 441559 253491 558075 346234 ...
## $ 한국인 : int [1:25] 556164 436223 324479 601691 503297 357703 410742 235154 554403 344166 ...
## $ 외국인 : int [1:25] 4888 4136 3523 6564 17632 14595 30817 18337 3672 2068 ...
## $ 고령자 : int [1:25] 65060 56161 56530 76032 70046 43953 58794 34170 74243 53488 ...
## $ 세대 : int [1:25] 231612 177407 142533 254257 255352 160798 171570 106066 217619 137378 ...
## $ 외국인비율: num [1:25] 0.871 0.939 1.074 1.079 3.385 ...
## $ 고령자비율: num [1:25] 11.6 12.8 17.2 12.5 13.4 ...
## $ cctv2017 : int [1:25] 4773 1494 946 1363 3314 1235 2741 1104 1750 787 ...# 5대범죄합계, 범죄발생율(범죄/인구 10만명)과 범죄검거율(검거/발생) 변수 생성
seoul_crime_pop_cctv <- seoul_crime_pop_cctv %>%
mutate(주요범죄발생 = 강간발생 + 강도발생 + 살인발생 + 절도발생 + 폭력발생,
주요범죄검거 = 강간검거 + 강도검거 + 살인검거 + 절도검거 + 폭력검거,
주요범죄율 = 주요범죄발생 / 인구 * 100000,
주요범죄검거율 = 주요범죄검거 / 주요범죄발생,
강간범죄율 = 강간발생 / 인구 * 100000,
강간검거율 = 강간검거 / 강간발생,
강도범죄율 = 강도발생 / 인구 * 100000,
강도검거율 = 강도검거 / 강도발생,
살인범죄율 = 살인발생 / 인구 * 100000,
살인검거율 = 살인검거 / 살인발생,
절도범죄율 = 절도발생 / 인구 * 100000,
절도검거율 = 절도검거 / 절도발생,
폭력범죄율 = 폭력발생 / 인구 * 100000,
폭력검거율 = 폭력검거 / 폭력발생)# 데이터 사본 만들기
seoul <- seoul_crime_pop_cctv
str(seoul)## tibble [25 x 33] (S3: tbl_df/tbl/data.frame)
## $ 자치구 : chr [1:25] "강남구" "강동구" "강북구" "강서구" ...
## $ 강간검거 : int [1:25] 496 169 153 253 323 208 181 212 155 115 ...
## $ 강간발생 : int [1:25] 607 172 208 316 379 261 328 240 180 104 ...
## $ 강도검거 : int [1:25] 24 12 5 6 6 8 6 5 7 3 ...
## $ 강도발생 : int [1:25] 20 10 7 4 7 13 8 5 9 3 ...
## $ 살인검거 : int [1:25] 7 6 8 11 7 5 8 5 4 1 ...
## $ 살인발생 : int [1:25] 7 5 8 11 8 6 7 5 4 1 ...
## $ 절도검거 : int [1:25] 1383 949 635 1113 1152 1168 869 674 757 417 ...
## $ 절도발생 : int [1:25] 3130 1645 1014 1888 1979 2220 1725 1141 1538 633 ...
## $ 폭력검거 : int [1:25] 3411 2109 2023 2544 2666 1900 2344 1676 2124 1116 ...
## $ 폭력발생 : int [1:25] 3956 2429 2156 2916 3152 2146 2827 1874 2478 1258 ...
## $ 인구 : int [1:25] 561052 440359 328002 608255 520929 372298 441559 253491 558075 346234 ...
## $ 한국인 : int [1:25] 556164 436223 324479 601691 503297 357703 410742 235154 554403 344166 ...
## $ 외국인 : int [1:25] 4888 4136 3523 6564 17632 14595 30817 18337 3672 2068 ...
## $ 고령자 : int [1:25] 65060 56161 56530 76032 70046 43953 58794 34170 74243 53488 ...
## $ 세대 : int [1:25] 231612 177407 142533 254257 255352 160798 171570 106066 217619 137378 ...
## $ 외국인비율 : num [1:25] 0.871 0.939 1.074 1.079 3.385 ...
## $ 고령자비율 : num [1:25] 11.6 12.8 17.2 12.5 13.4 ...
## $ cctv2017 : int [1:25] 4773 1494 946 1363 3314 1235 2741 1104 1750 787 ...
## $ 주요범죄발생 : int [1:25] 7720 4261 3393 5135 5525 4646 4895 3265 4209 1999 ...
## $ 주요범죄검거 : int [1:25] 5321 3245 2824 3927 4154 3289 3408 2572 3047 1652 ...
## $ 주요범죄율 : num [1:25] 1376 968 1034 844 1061 ...
## $ 주요범죄검거율: num [1:25] 0.689 0.762 0.832 0.765 0.752 ...
## $ 강간범죄율 : num [1:25] 108.2 39.1 63.4 52 72.8 ...
## $ 강간검거율 : num [1:25] 0.817 0.983 0.736 0.801 0.852 ...
## $ 강도범죄율 : num [1:25] 3.565 2.271 2.134 0.658 1.344 ...
## $ 강도검거율 : num [1:25] 1.2 1.2 0.714 1.5 0.857 ...
## $ 살인범죄율 : num [1:25] 1.25 1.14 2.44 1.81 1.54 ...
## $ 살인검거율 : num [1:25] 1 1.2 1 1 0.875 ...
## $ 절도범죄율 : num [1:25] 558 374 309 310 380 ...
## $ 절도검거율 : num [1:25] 0.442 0.577 0.626 0.59 0.582 ...
## $ 폭력범죄율 : num [1:25] 705 552 657 479 605 ...
## $ 폭력검거율 : num [1:25] 0.862 0.868 0.938 0.872 0.846 ...데이터 탐색 및 시각화 하기
서울시 범죄 데이터 탐색 질문 (2017년 기준)
- 주요범죄 발생건수가 높은 구(낮은 구)는?
- 주요범죄 발생율이 높은 구(낮은 구)는?
- 주요범죄 검거율이 높은 구(낮은 구)는?
- 각 범죄의 발생율이 높은 구(낮은 구)는?
- 각 범죄의 검거율이 높은 구(낮은 구)는?
- 각 범죄 발생율의 상관관계는?
- 각 범죄 검거율의 상관관계는?
- 주요 범죄 발생건수와 발생율의 상관관계는?
- 인구와 주요범죄 발생건수의 상관관계는?
- 인구와 주요범죄 발생율의 상관관계는?
- 죄종별 인구와 범죄발생율의 상관관계는?
- CCTV와 주요범죄 발생건수의 상관관계는?
- CCTV와 주요범죄율의 상관관계는?
- 죄종별 CCTV와 범죄율의 상관관계는?
- CCTV와 주요범죄 검거율의 상관관계는?
- 죄종별 CCTV와 주요범죄 검거율의 상관관계는?
- 외국인 비율과 주요범죄율의 상관관계는?
- 죄종별 외국인 비율과 범죄율의 상관관계는?
- 고령자 비율과 주요범죄율의 상관관계는?
- 죄종별 고령자 비율과 범죄율의 상관관계는?
주요범죄 발생건수가 높은 구(낮은 구)는?
g1 <- seoul %>%
mutate(자치구 = fct_reorder(자치구, 주요범죄발생)) %>%
ggplot(aes(자치구, 주요범죄발생)) +
geom_col(fill = "skyblue") +
coord_flip() +
labs(title = "서울시 자치구별 주요범죄 발생건수", x = "자치구", y = "발생건수") +
theme_light()
print(g1)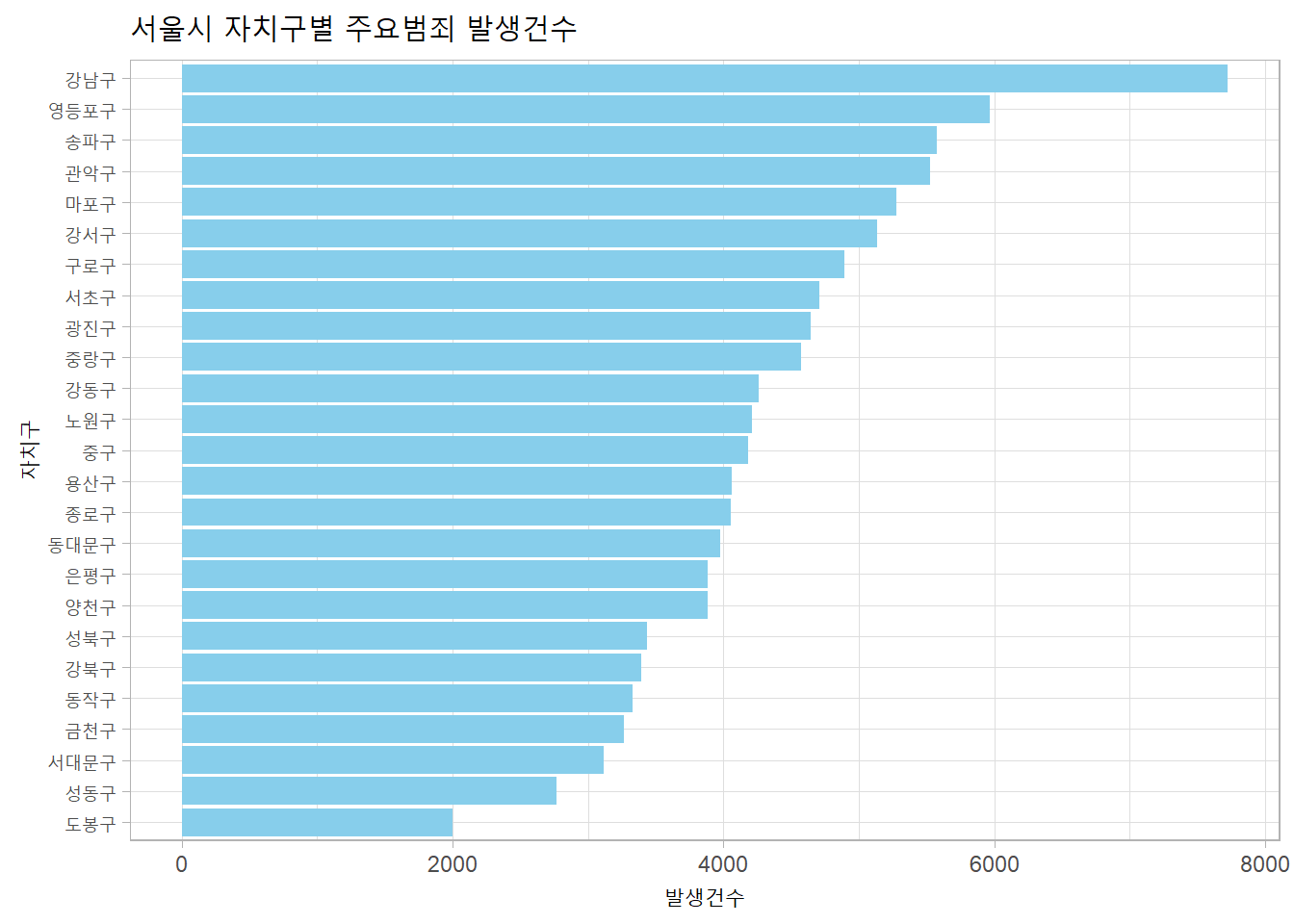
주요범죄 발생율이 높은 구(낮은 구)는?
g2 <- seoul %>%
mutate(자치구 = fct_reorder(자치구, 주요범죄율)) %>%
ggplot(aes(자치구, 주요범죄율)) +
geom_col(fill = "steelblue") +
coord_flip() +
labs(title = "서울시 자치구별 주요범죄율", x = "자치구", y = "범죄율") +
theme_light()
print(g2)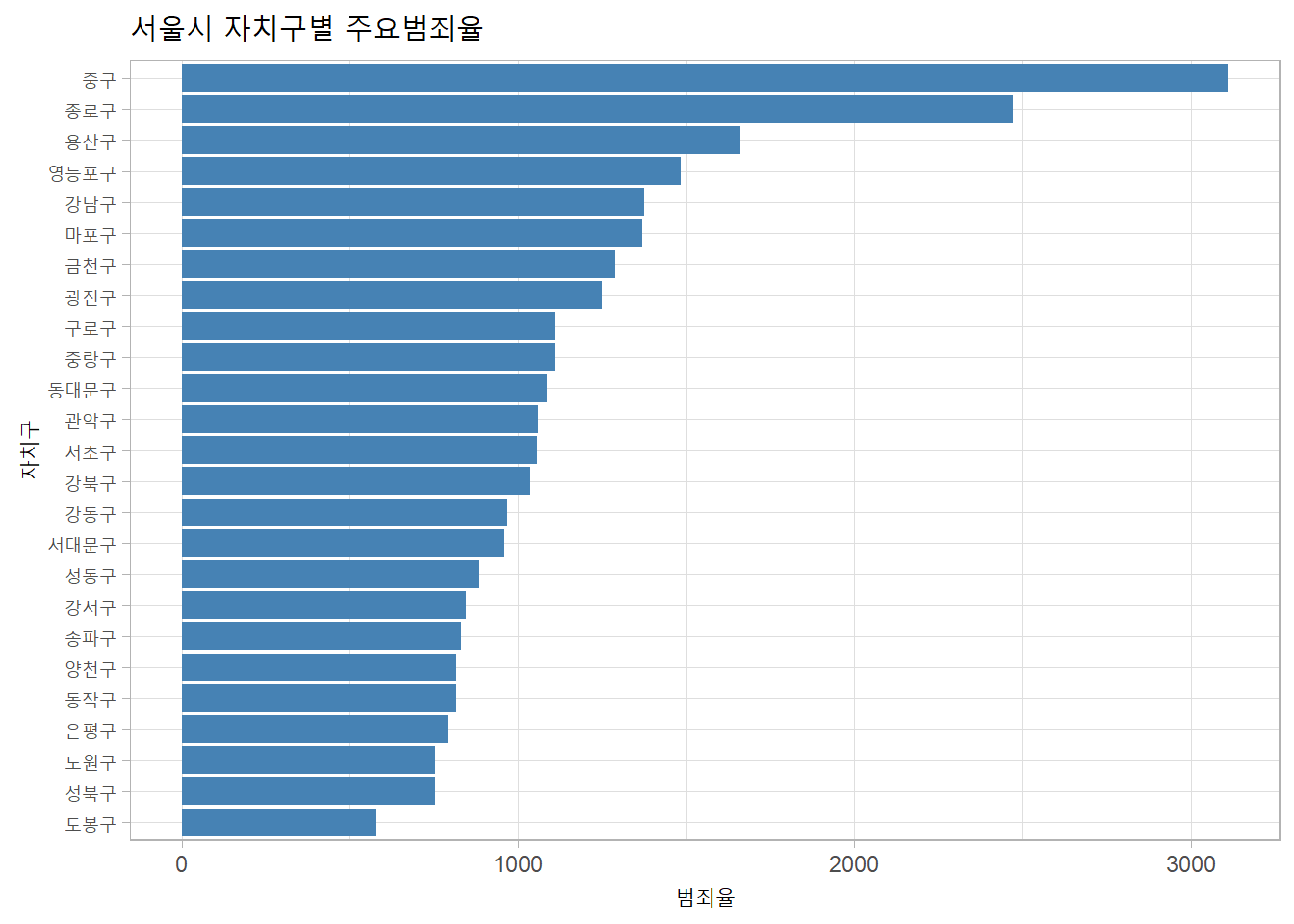
자치구별 주요범죄 발생건수와 발생율 비교
grid.arrange(g1, g2, nrow=1, ncol=2)
주요범죄 검거율이 높은 구(낮은 구)는?
g3 <- seoul %>%
mutate(자치구 = fct_reorder(자치구, 주요범죄검거율)) %>%
ggplot(aes(자치구, 주요범죄검거율)) +
geom_segment(aes(xend=자치구, yend=0)) +
geom_point(size=3, color="orange") +
coord_flip() +
labs(title = "서울시 자치구별 주요범죄 검거율", x = "자치구", y = "검거율") +
theme_light()
print(g3)
자치구별 주요범죄 발생율과 검거율 비교
grid.arrange(g2, g3, nrow=1, ncol=2)
각 범죄의 발생율이 높은 구(낮은 구)는?
# 죄종별 범죄율의 변수명 리스트
offense_list <- c("강간범죄율", "강도범죄율", "살인범죄율", "절도범죄율", "폭력범죄율")# 막대 그래프
seoul %>%
select(자치구, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = 자치구, y = 범죄율, fill = 죄종)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ 죄종, scales = "free") +
coord_flip() +
labs(title = "서울시 자치구별 주요범죄 발생율", x = NULL, y = NULL) +
theme_test()## Note: Using an external vector in selections is ambiguous.
## i Use `all_of(offense_list)` instead of `offense_list` to silence this message.
## i See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
## This message is displayed once per session.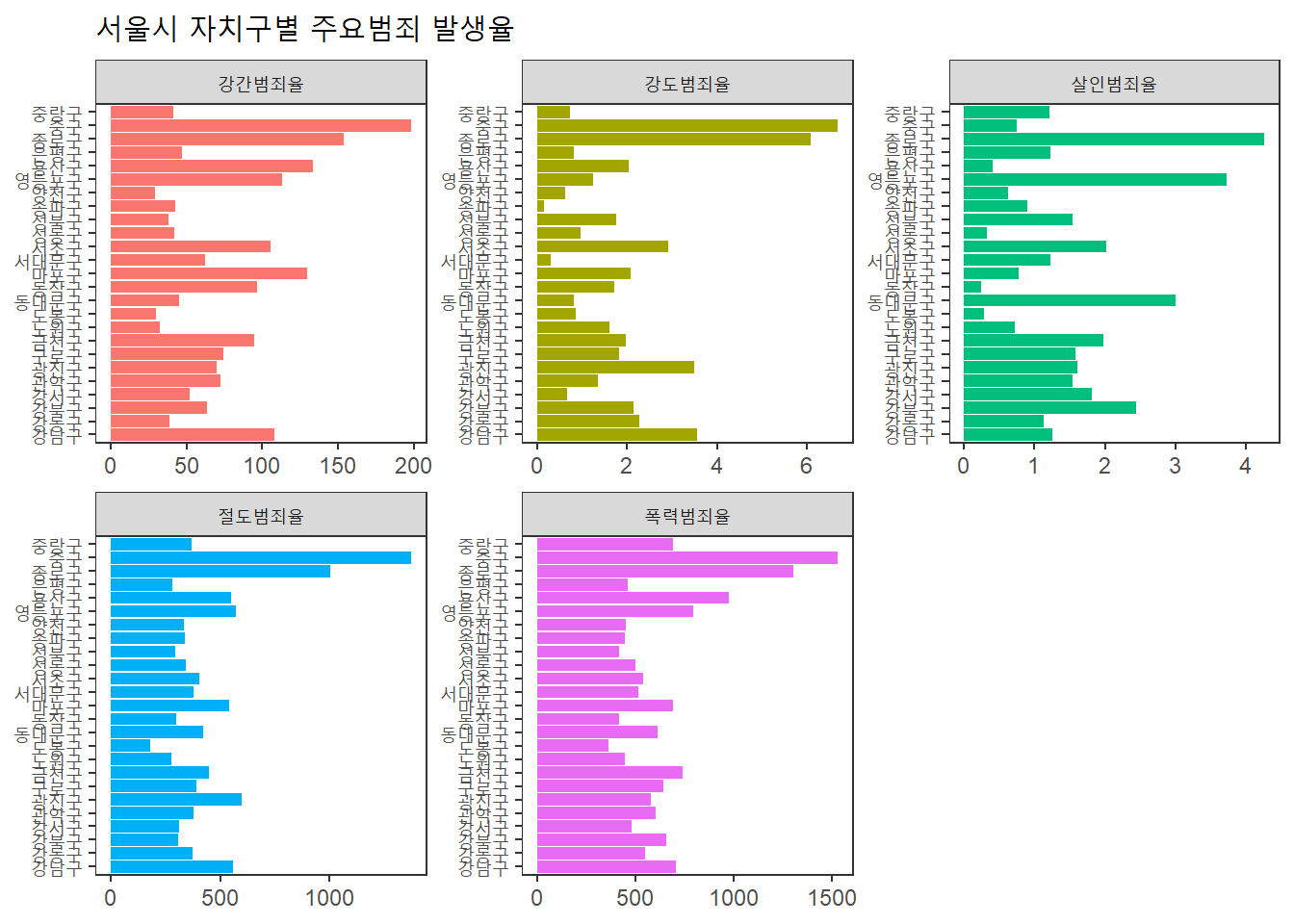
# 히트맵
seoul %>%
select(자치구, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = 죄종, y = 자치구)) +
geom_tile(aes(fill = 범죄율), show.legend = FALSE) +
scale_fill_gradient(low="white", high="purple3") +
geom_text(aes(label = format(범죄율, digits = 4))) +
labs(title = "서울시 자치구별 주요범죄 발생율", x = NULL, y = NULL) +
theme_minimal()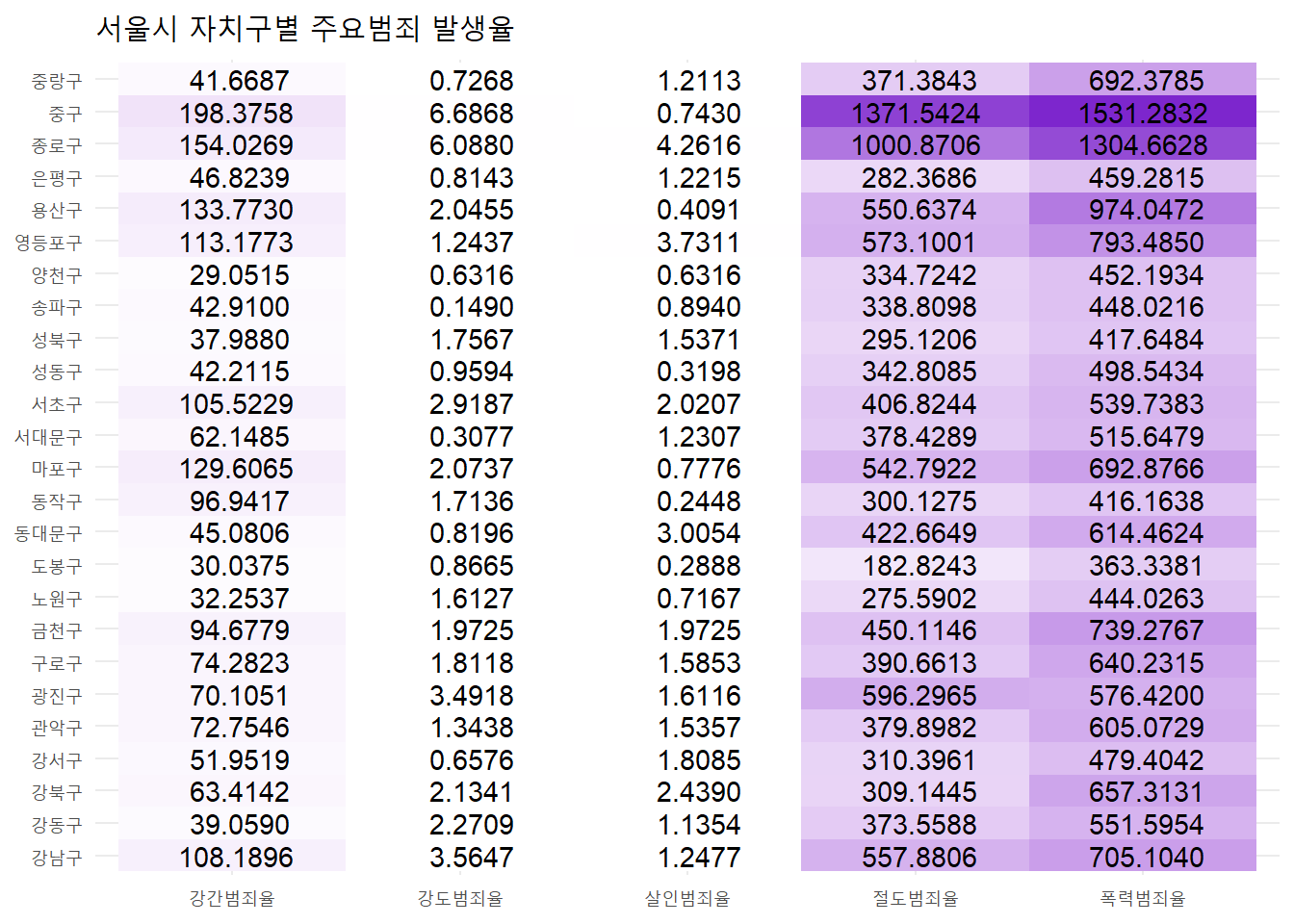
각 범죄의 검거율이 높은 구(낮은 구)는?
# 죄종별 검거율의 변수명 리스트
arrest_list <- c("강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율")# 막대그래프
seoul %>%
select(자치구, arrest_list) %>%
gather(key = "죄종", value = "검거율", arrest_list) %>%
ggplot(aes(x = 자치구, y = 검거율, fill = 죄종)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ 죄종, scales = "free") +
coord_flip() +
labs(title = "서울시 자치구별 주요범죄 검거율", x = NULL, y = NULL) +
theme_test()## Note: Using an external vector in selections is ambiguous.
## i Use `all_of(arrest_list)` instead of `arrest_list` to silence this message.
## i See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
## This message is displayed once per session.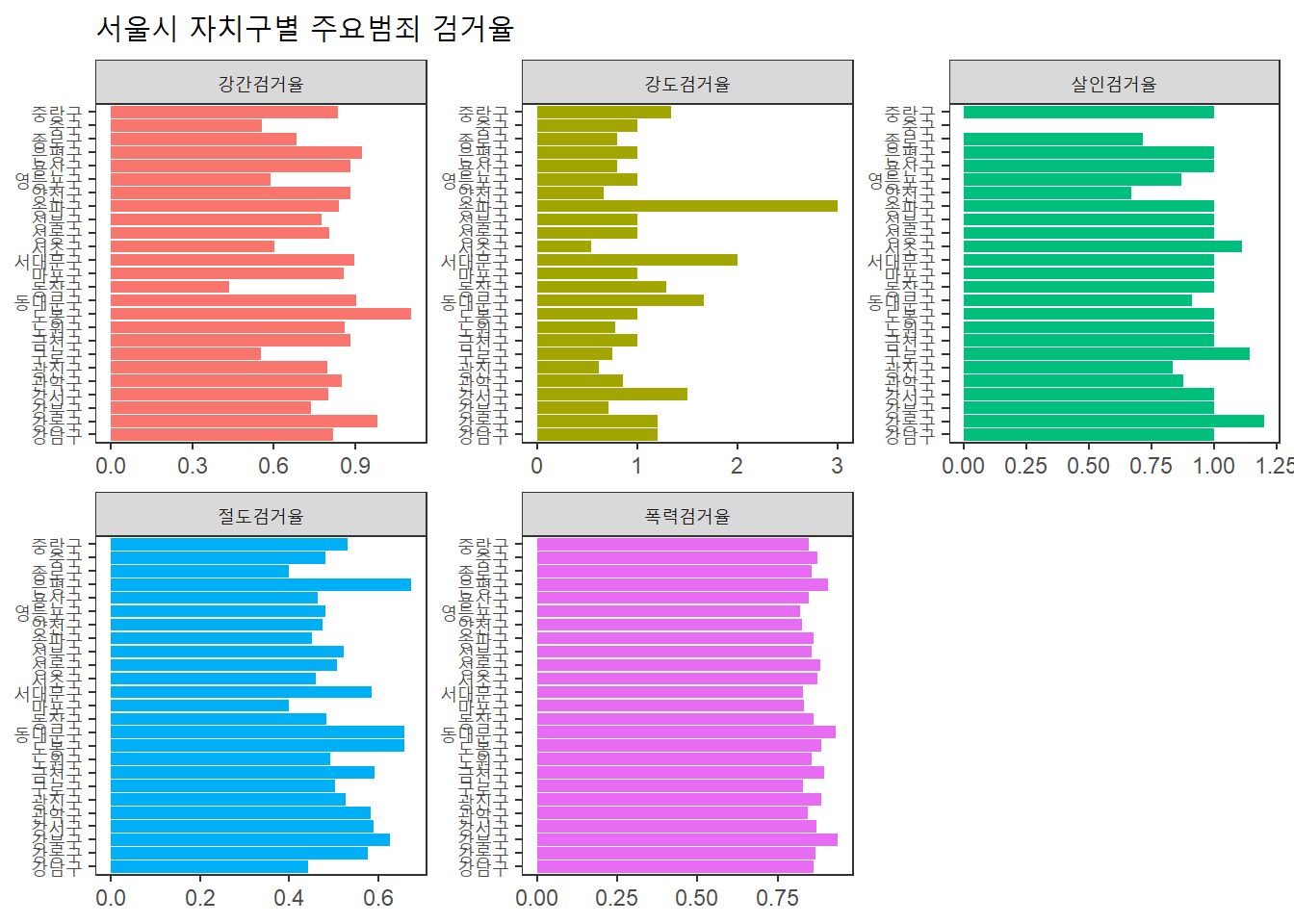
# 히트맵
seoul %>%
select(자치구, arrest_list) %>%
gather(key = "죄종", value = "검거율", arrest_list) %>%
ggplot(aes(x = 죄종, y = 자치구)) +
geom_tile(aes(fill = 검거율), show.legend = FALSE) +
scale_fill_gradient(low="white", high="purple3") +
geom_text(aes(label = format(검거율, digits = 4))) +
labs(title = "서울시 자치구별 주요범죄 검거율", x = NULL, y = NULL) +
theme_minimal()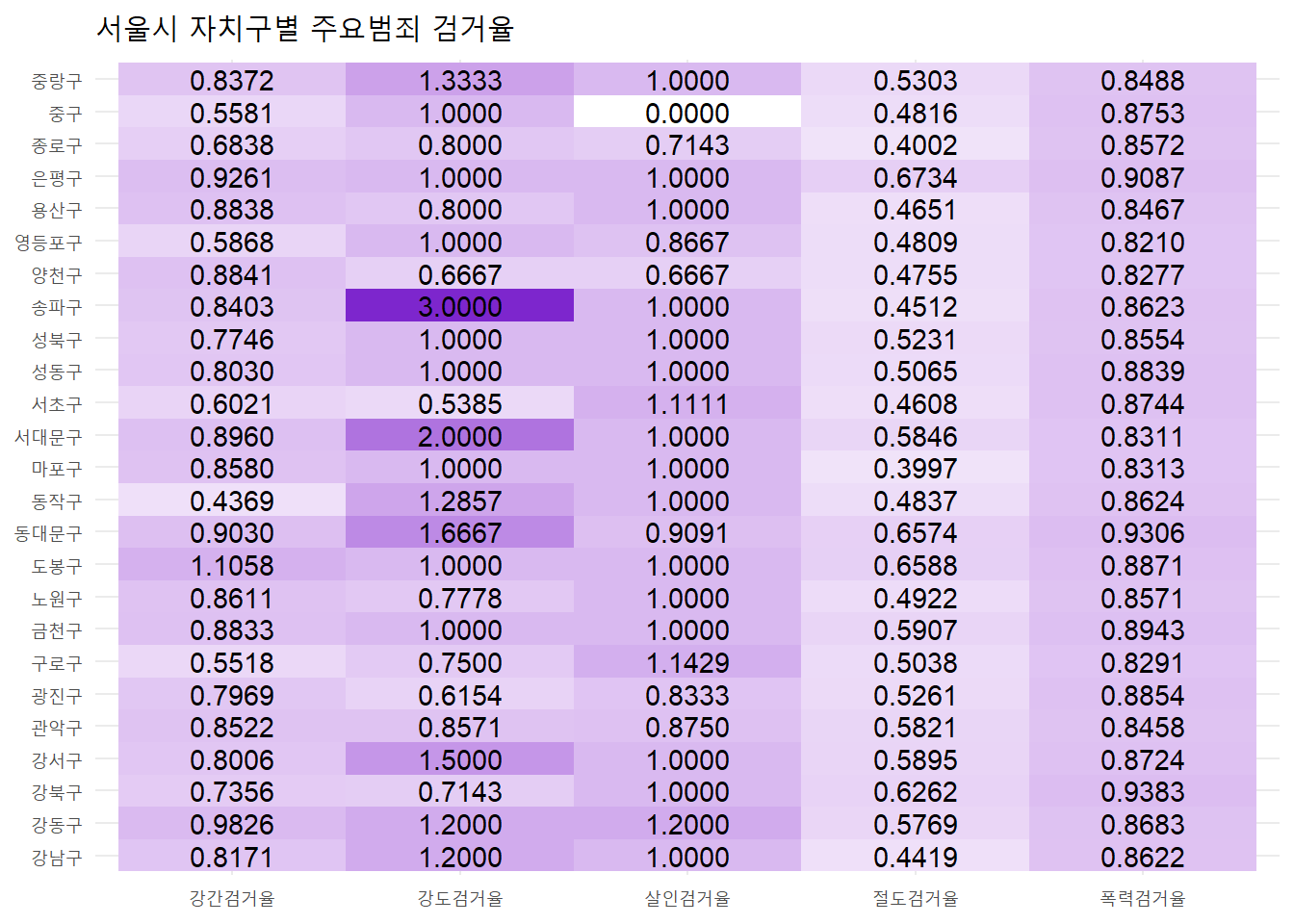
각 범죄 발생율의 상관관계는?
# 변수간 상관계수
seoul %>%
select(offense_list) %>%
ggcorr(label=TRUE, size = 5)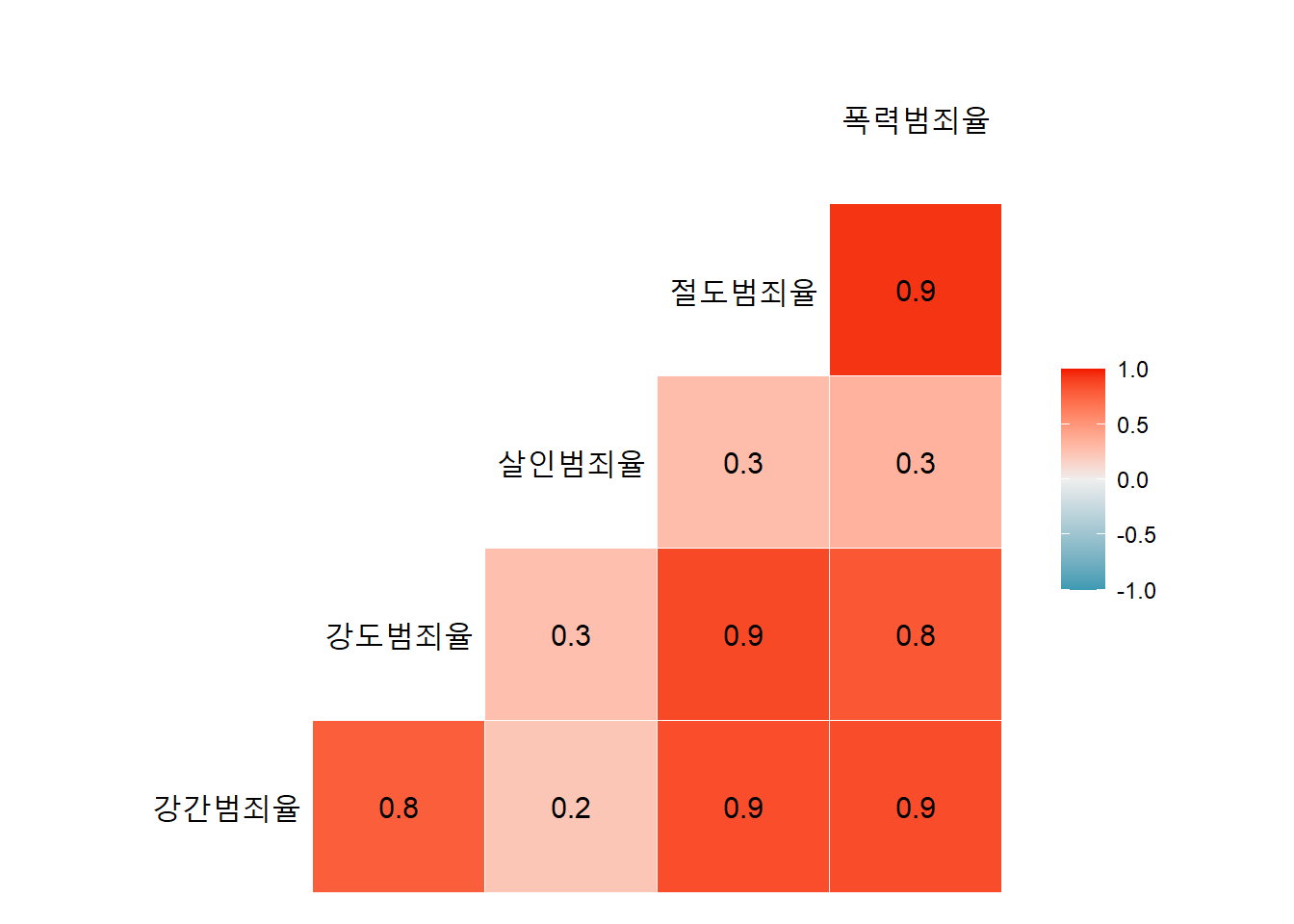
# 변수간 상관관계 산점도 및 상관계수
seoul %>%
select(offense_list) %>%
ggscatmat(alpha = 0.7)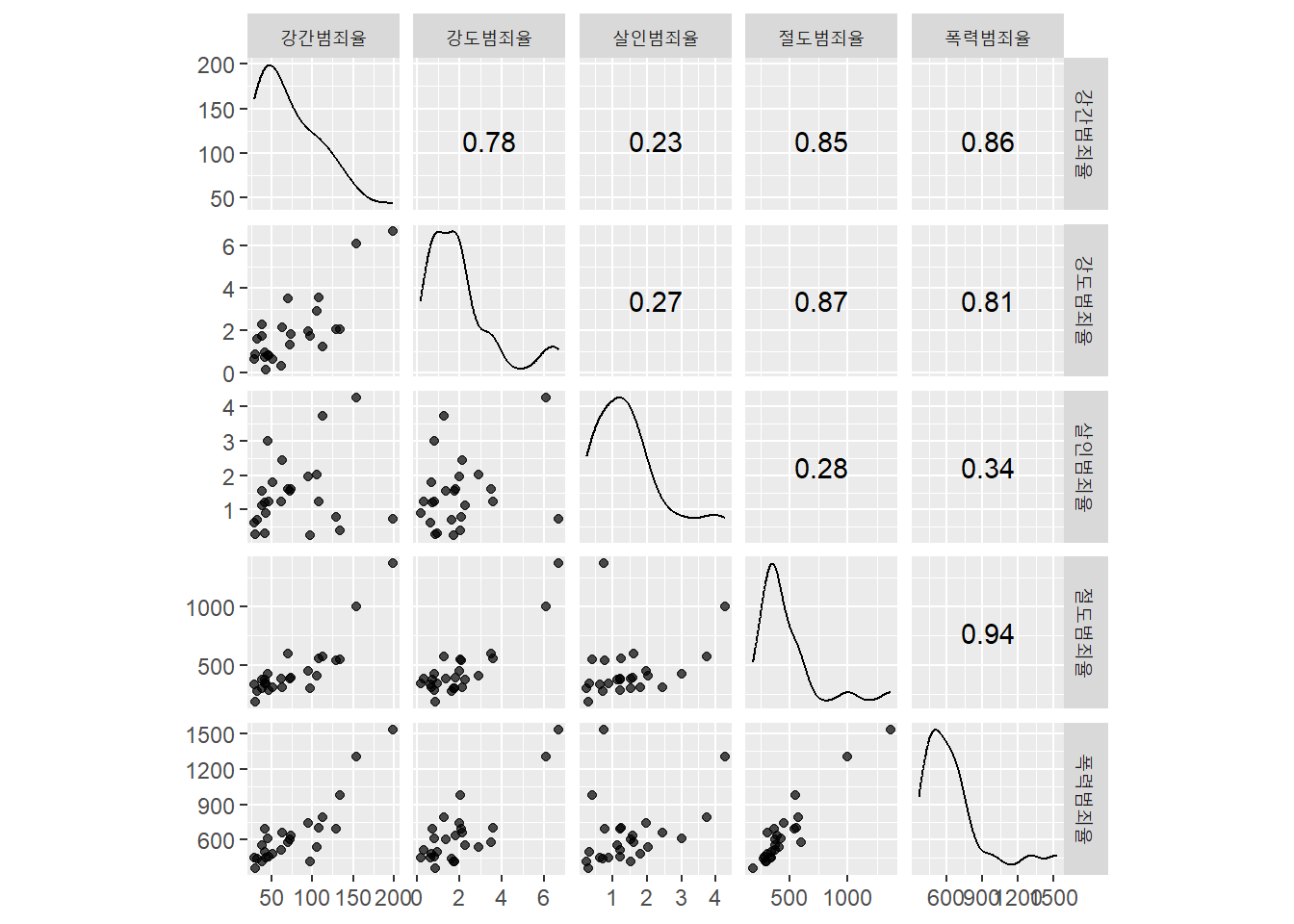
각 범죄 검거율의 상관관계는?
seoul %>%
select(arrest_list) %>%
ggcorr(label=TRUE, size = 5)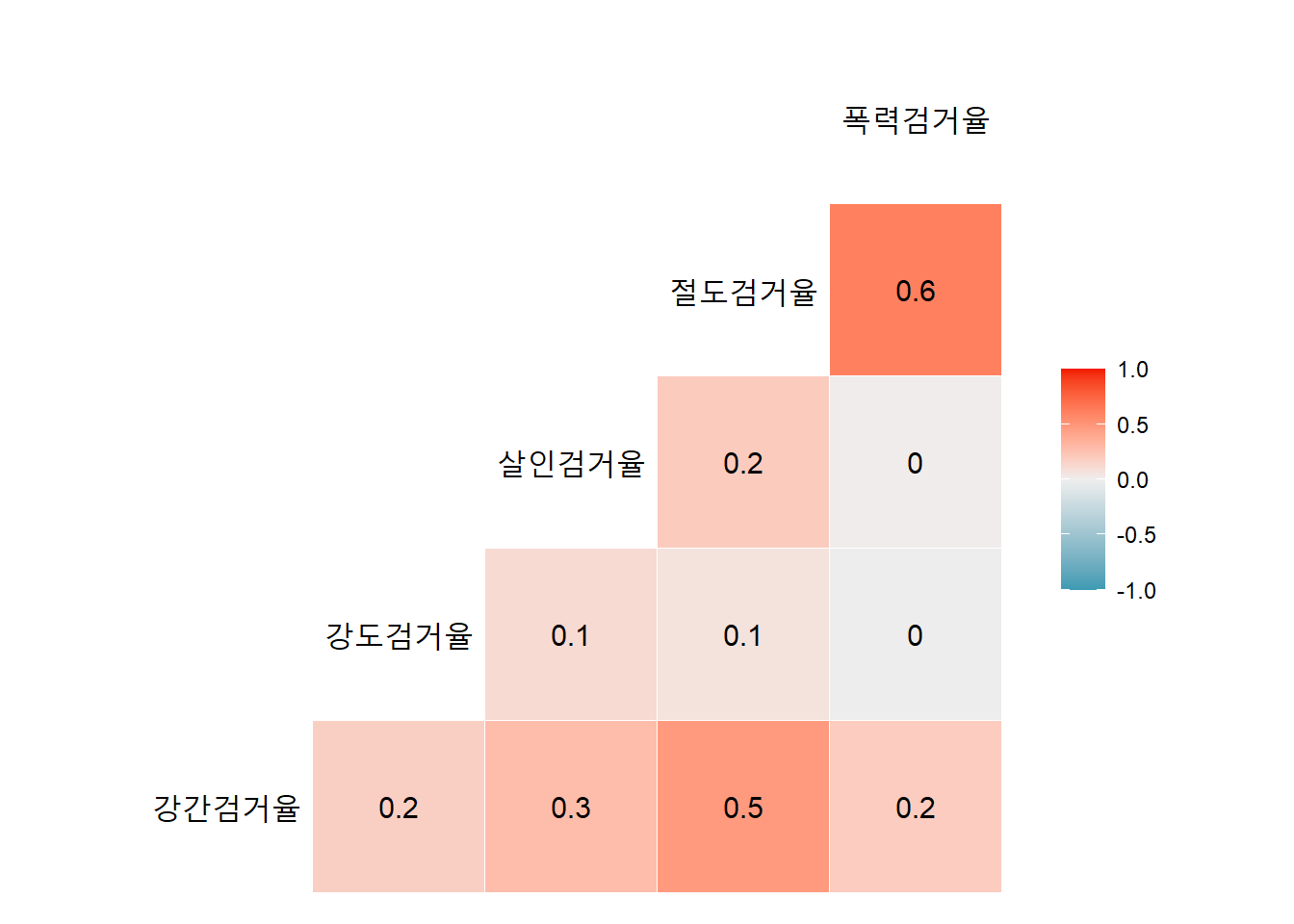
seoul %>%
select(arrest_list) %>%
ggscatmat(alpha = 0.7)
주요범죄 발생건수와 주요범죄 발생율의 상관관계는?
seoul %>%
ggplot(aes(x = 주요범죄발생, y = 주요범죄율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -0.5, hjust = 0.5)) +
labs(title = "서울시 주요범죄 발생건수와 주요범죄율") +
annotate("text", x = 7000, y = 3000, size = 5,
label = paste("r ==", round(cor(seoul$주요범죄발생, seoul$주요범죄율),2)),
parse = TRUE) +
theme_test()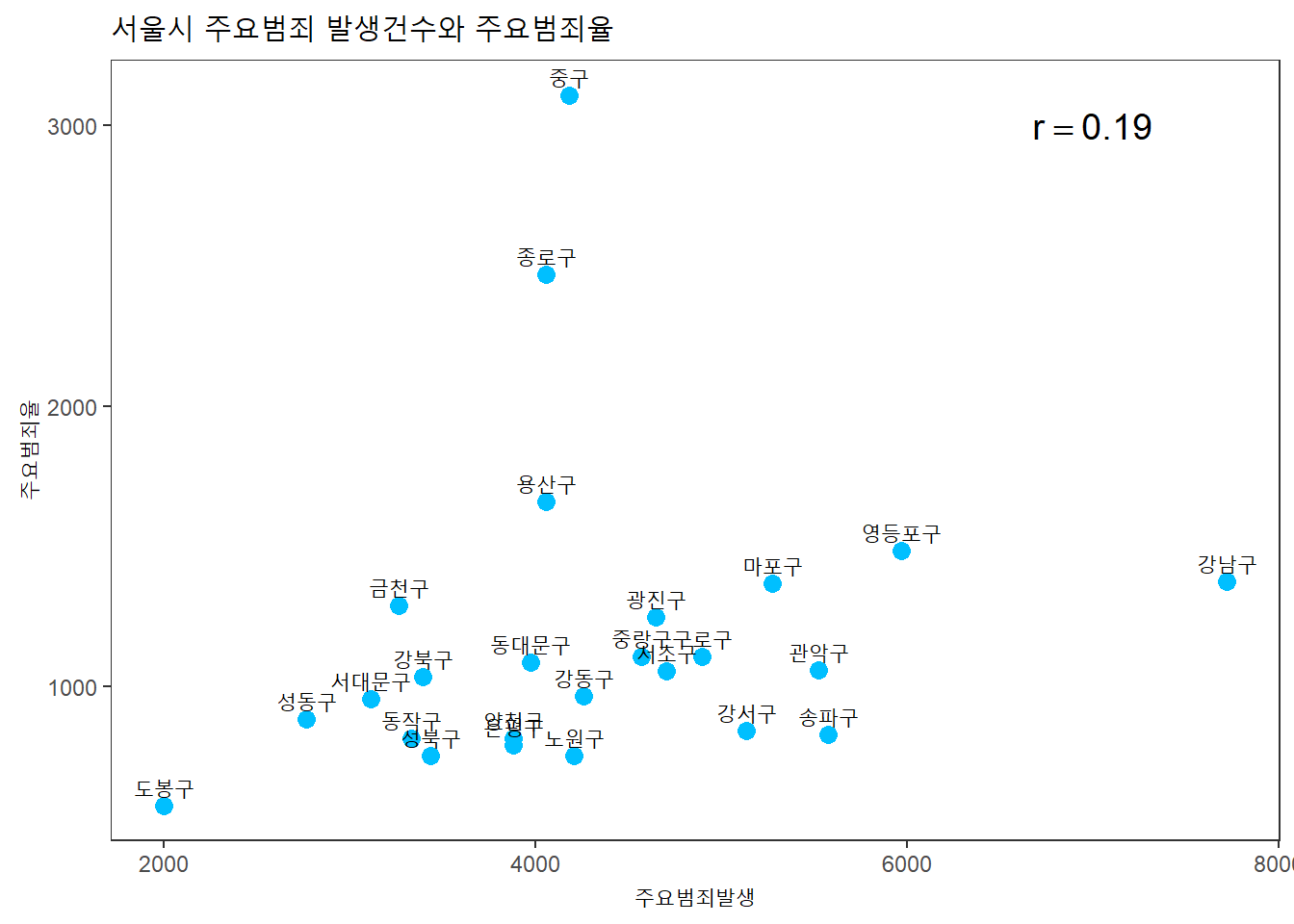
인구와 주요범죄 발생건수의 상관관계는?
seoul %>%
ggplot(aes(x = 인구, y = 주요범죄발생)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
labs(title = "서울시 인구과 주요범죄 발생건수") +
annotate("text", x = 200000, y = 7000, size = 5,
label = paste("r ==", round(cor(seoul$인구, seoul$주요범죄발생),2)),
parse = TRUE) +
theme_test()
인구와 주요범죄 발생율의 상관관계는?
seoul %>%
ggplot(aes(x = 인구, y = 주요범죄율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
labs(title = "서울시 인구과 주요범죄율") +
annotate("text", x = 600000, y = 3000, size = 5,
label = paste("r ==", round(cor(seoul$인구, seoul$주요범죄율),2)),
parse = TRUE) +
theme_test()
죄종별 인구와 범죄발생율의 상관관계는?
seoul %>%
select(자치구, 인구, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = 인구, y = 범죄율)) +
geom_point(color = "deepskyblue", size = 2) +
facet_wrap(~ 죄종, scales = "free") +
geom_text(aes(label = 자치구, vjust = 0, hjust = -0.3), check_overlap = TRUE) +
labs(title = "서울시 인구과 죄종별 범죄율") +
theme_test()
CCTV와 주요범죄 발생건수의 상관관계는?
seoul %>%
ggplot(aes(x = cctv2017, y = 주요범죄발생)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
labs(title = "서울시 CCTV와 주요범죄 발생건수") +
annotate("text", x = 3000, y = 7000, size = 5,
label = paste("r ==", round(cor(seoul$cctv2017, seoul$주요범죄발생),2)),
parse = TRUE) +
theme_test()
CCTV와 주요범죄율의 상관관계는?
seoul %>%
ggplot(aes(x = cctv2017, y = 주요범죄율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
labs(title = "서울시 CCTV와 주요범죄율") +
annotate("text", x = 3000, y = 3000, size = 5,
label = paste("r ==", round(cor(seoul$cctv2017, seoul$주요범죄율),2)),
parse = TRUE) +
theme_test()
죄종별 CCTV와 범죄율의 상관관계는?
seoul %>%
select(자치구, cctv2017, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = cctv2017, y = 범죄율)) +
geom_point(color = "deepskyblue", size = 2) +
facet_wrap(~ 죄종, scales = "free") +
geom_text(aes(label = 자치구, vjust = 0, hjust = -0.3), check_overlap = TRUE) +
labs(title = "서울시 CCTV와 죄종별 범죄율") +
theme_test()
CCTV와 주요범죄 검거율의 상관관계는?
seoul %>%
ggplot(aes(x = cctv2017, y = 주요범죄검거율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
labs(title = "서울시 CCTV와 주요범죄 검거율") +
annotate("text", x = 3000, y = 0.8, size = 5,
label = paste("r ==", round(cor(seoul$cctv2017, seoul$주요범죄검거율),2)),
parse = TRUE) +
theme_test()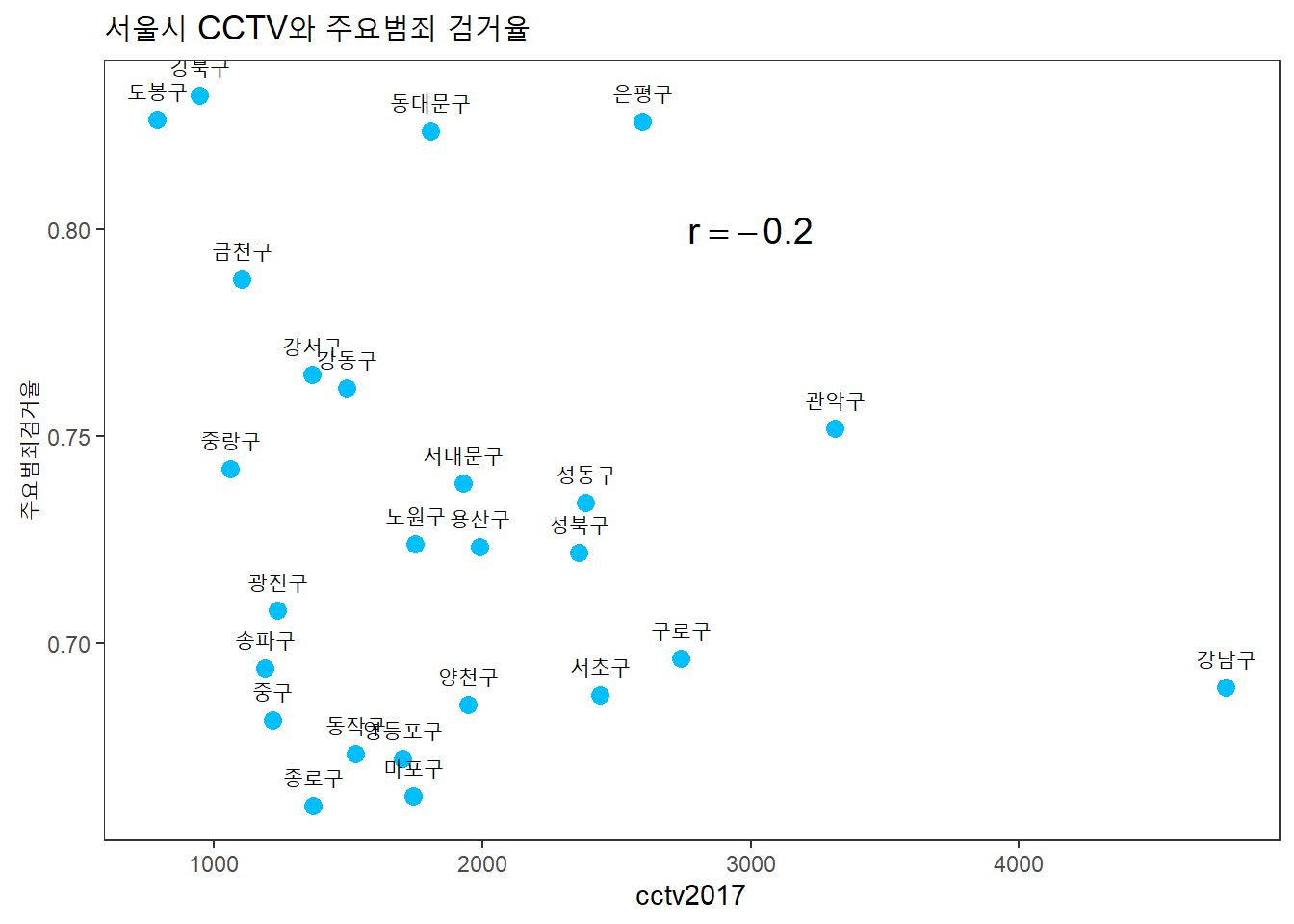
죄종별 CCTV와 주요범죄 검거율의 상관관계는?
seoul %>%
select(자치구, cctv2017, arrest_list) %>%
gather(key = "죄종", value = "검거율", arrest_list) %>%
ggplot(aes(x = cctv2017, y = 검거율)) +
geom_point(color = "deepskyblue", size = 2) +
facet_wrap(~ 죄종, scales = "free") +
geom_text(aes(label = 자치구, vjust = 0, hjust = -0.3), check_overlap = TRUE) +
labs(title = "서울시 CCTV와 죄종별 검거율") +
theme_test()
외국인 비율과 주요범죄율의 상관관계는?
seoul %>%
ggplot(aes(x = 외국인비율, y = 주요범죄율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
geom_smooth(method = lm, color = "deeppink") +
labs(title = "서울시 외국인비율과 주요범죄율") +
annotate("text", x = 8, y = 3000, size = 5,
label = paste("r ==", round(cor(seoul$외국인비율, seoul$주요범죄율),2)),
parse = TRUE) +
theme_test()## `geom_smooth()` using formula 'y ~ x'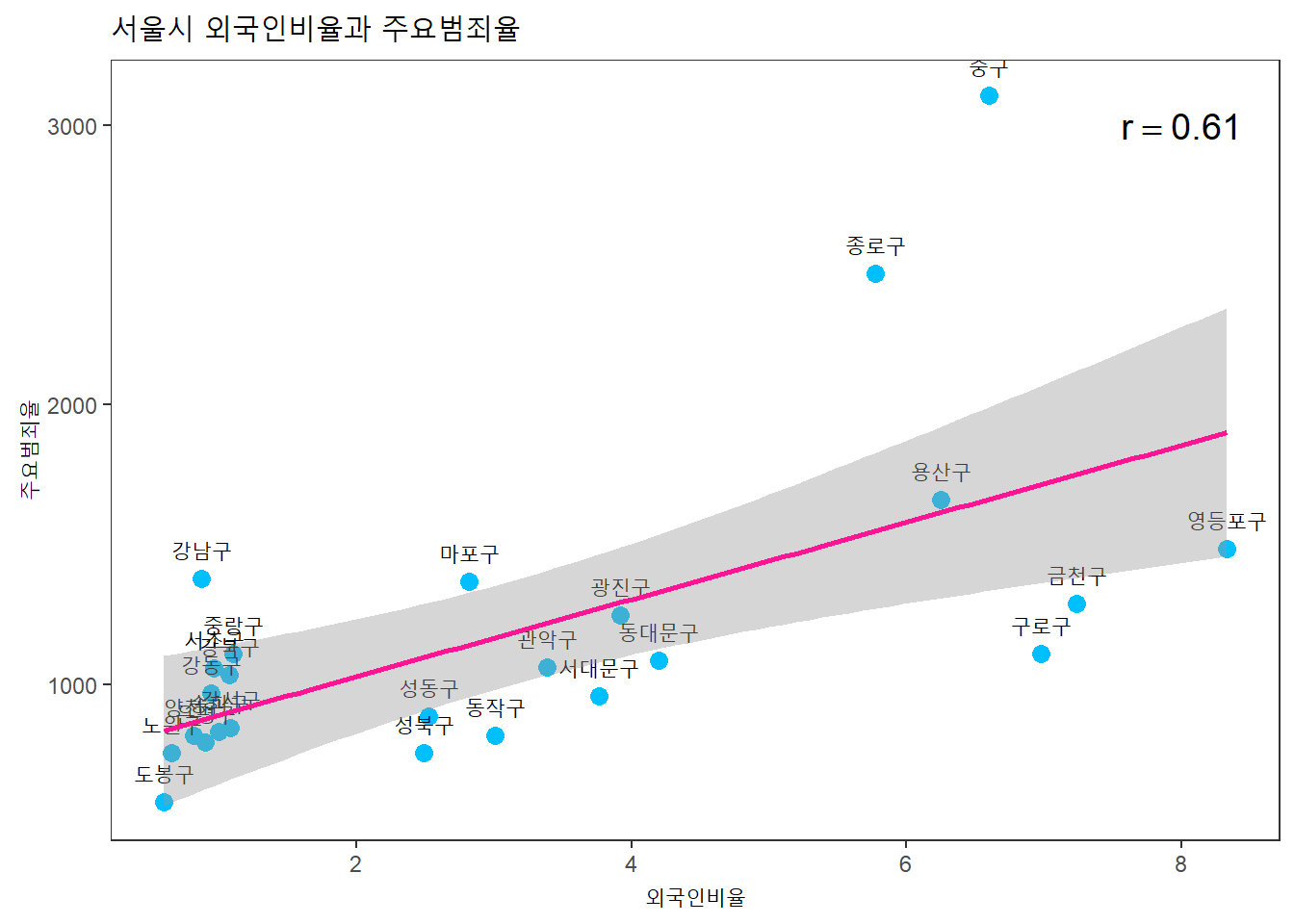
죄종별 외국인 비율과 범죄율의 상관관계는?
seoul %>%
select(자치구, 외국인비율, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = 외국인비율, y = 범죄율)) +
geom_point(color = "deepskyblue", size = 2) +
facet_wrap(~ 죄종, scales = "free") +
geom_text(aes(label = 자치구, vjust = 0, hjust = -0.3), check_overlap = TRUE) +
geom_smooth(method = lm, color = "deeppink") +
labs(title = "서울시 외국인비율과 죄종별 범죄율") +
theme_test()## `geom_smooth()` using formula 'y ~ x'
고령자 비율과 주요범죄율의 상관관계는?
seoul %>%
ggplot(aes(x = 고령자비율, y = 주요범죄율)) +
geom_point(color = "deepskyblue", size = 3) +
geom_text(aes(label = 자치구, vjust = -1, hjust = 0.5)) +
geom_smooth(method = lm, color = "deeppink") +
labs(title = "서울시 고령자비율과 주요범죄율") +
annotate("text", x = 17, y = 3000, size = 5,
label = paste("r ==", round(cor(seoul$고령자비율, seoul$주요범죄율),2)),
parse = TRUE) +
theme_test()## `geom_smooth()` using formula 'y ~ x'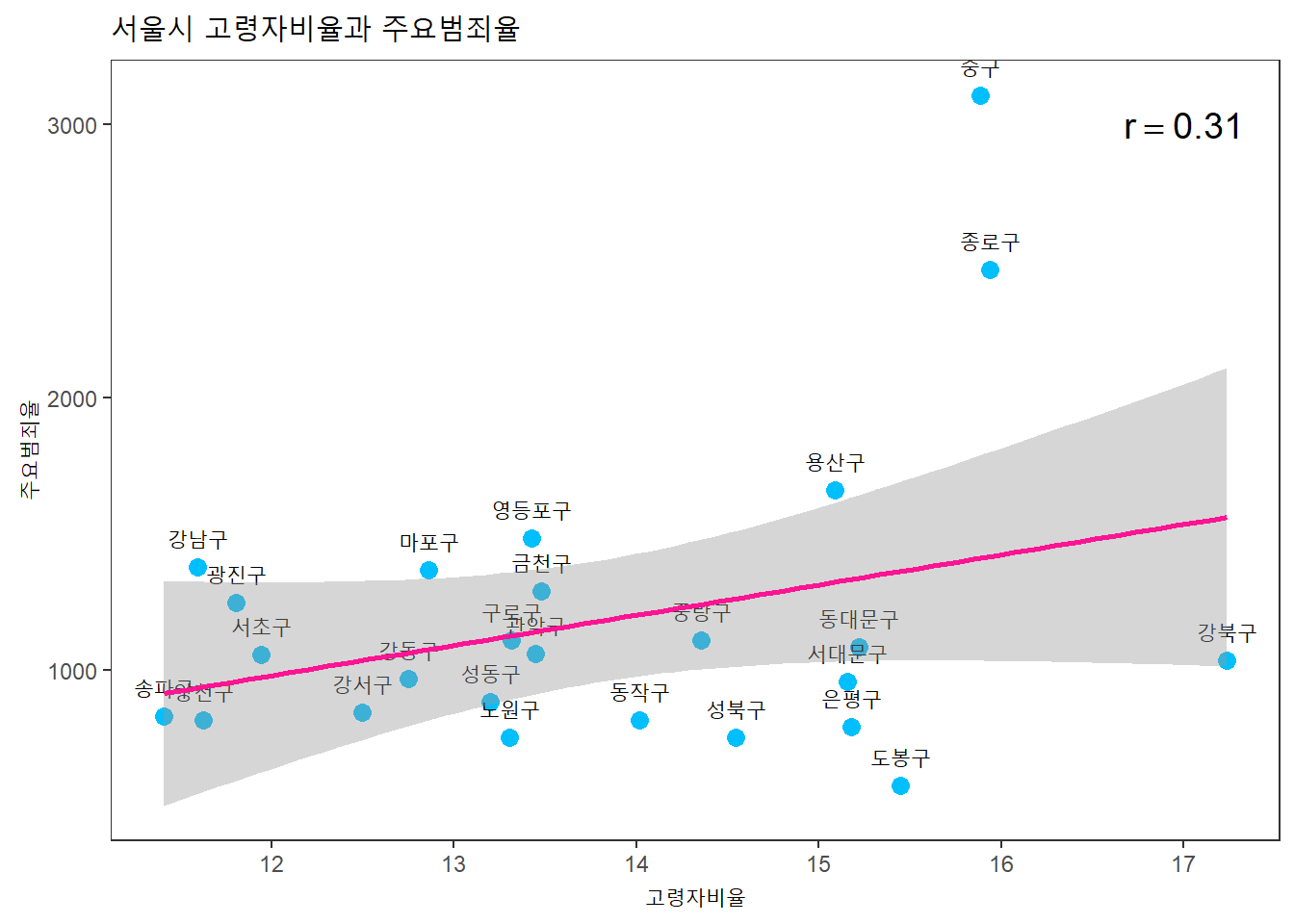
죄종별 고령자 비율과 범죄율의 상관관계는?
seoul %>%
select(자치구, 고령자비율, offense_list) %>%
gather(key = "죄종", value = "범죄율", offense_list) %>%
ggplot(aes(x = 고령자비율, y = 범죄율)) +
geom_point(color = "deepskyblue", size = 2) +
facet_wrap(~ 죄종, scales = "free") +
geom_text(aes(label = 자치구, vjust = 0, hjust = -0.3), check_overlap = TRUE) +
geom_smooth(method = lm, color = "deeppink") +
labs(title = "서울시 고령자비율과 죄종별 범죄율") +
theme_test()## `geom_smooth()` using formula 'y ~ x'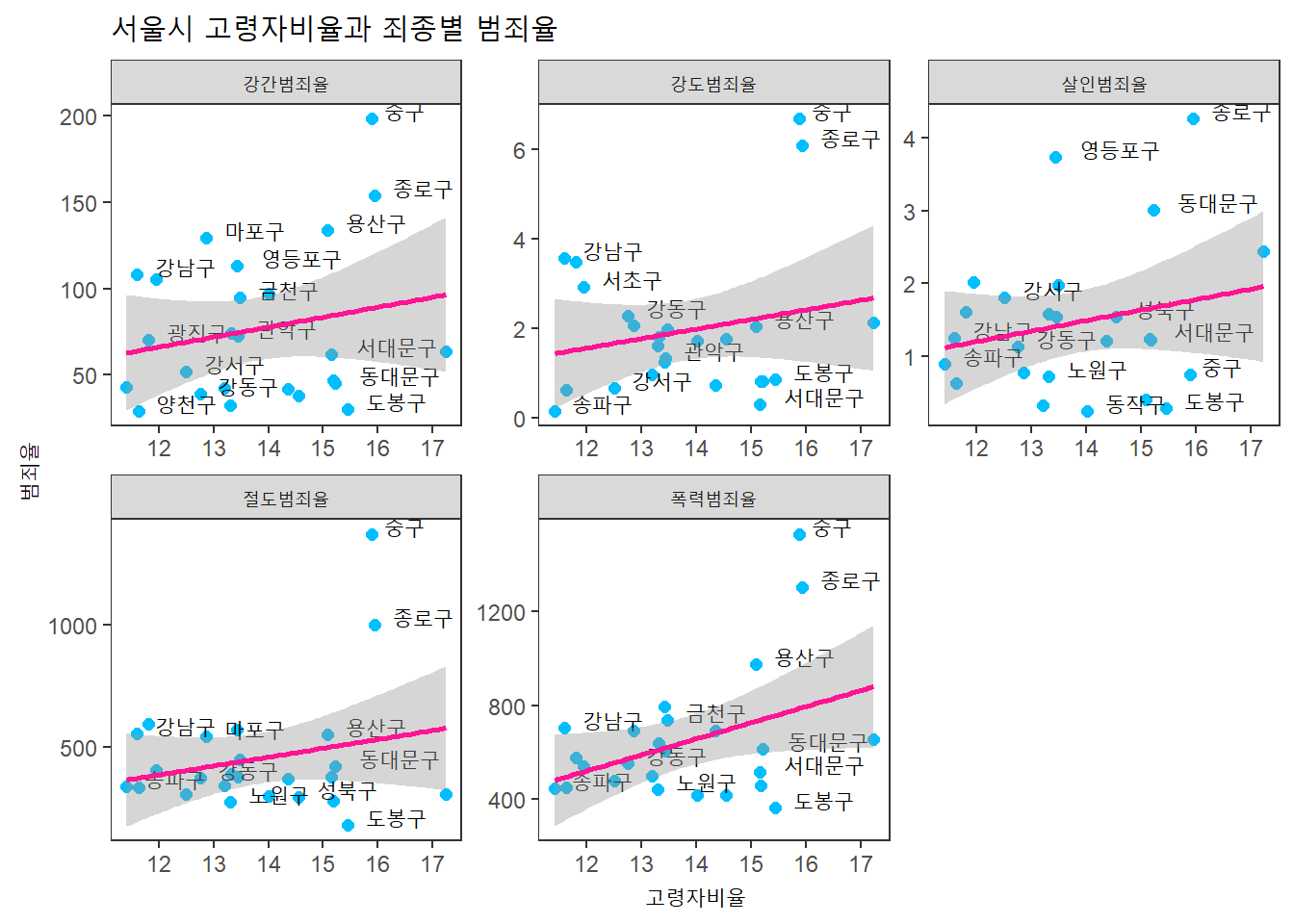
참고 : 민형기(2017)의 ’파이썬으로 데이터 주무르기’를 참고하여 R 언어로 분석